The Complete Guide to Building Scalable AI Systems for Business

I’ll be blunt: most “AI systems for business” collapse the moment traffic spikes, data grows, or the model faces a real-world scenario it wasn’t trained for. I’ve watched brilliant teams build models that performed beautifully in a Jupyter notebook… then fell apart when exposed to messy human behavior, inconsistent data, or a surge in user requests.
Scalable AI systems aren’t just models. They’re ecosystems - moving parts that work reliably even when your business hits 10x demand or expands across regions.
I’ve built scalable AI systems for logistics, fintech, retail, healthcare, and startups trying to grow without breaking their infrastructure budget. And if there’s one thing I’ve learned, it’s this: AI doesn’t fail because of math; it fails because of architecture.
Let’s fix that.
What Is a Scalable AI System?
A scalable AI system is one that maintains performance, accuracy, and speed even as data, users, and workloads grow. Not “sort of works.” Not “works when the engineer is watching.” Works reliably - every time.
Core characteristics
Can handle increasing data volumes without retraining chaos
Supports multiple models, versions, and environments
Responds quickly even when usage spikes
Easily integrates with existing business systems
Adapts to new data through structured retraining
Real-world examples
A retail demand forecasting engine that handles seasonal spikes without degrading accuracy.
A healthcare NLP tool processing millions of clinical notes while keeping inference latency stable.
An AI Voice Agent Company scaling their conversational models across languages.
A fintech risk-scoring system updating models in real-time as fraud patterns evolve.
Key Components of a Scalable AI Architecture
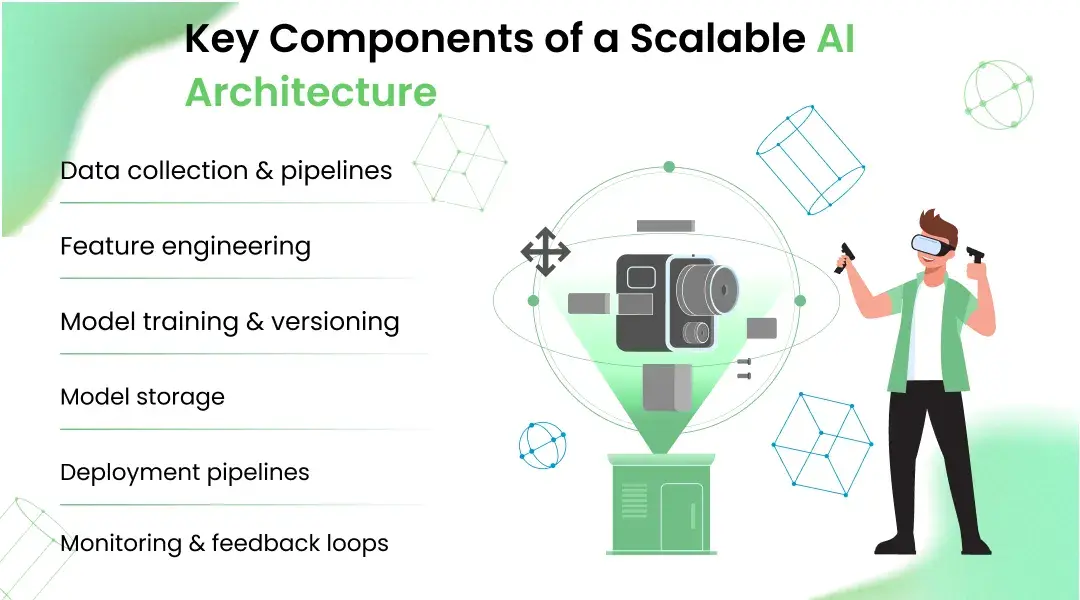
1. Data collection & pipelines
If the data pipeline is brittle, the model will be too. Scalable systems use:
Stream processors
Managed workflows (Airflow, Prefect)
Schema validation
Automated failover
2. Feature engineering
Reusable feature stores help teams avoid repeating transformations endlessly.
3. Model training & versioning
Every model should have:
Traceable datasets
Logged hyperparameters
Versioned artifacts
Rollback-ready deployments
4. Model storage
Use object storage (S3, GCS) or artifact repositories.
5. Deployment pipelines
CI/CD for ML - not optional.
6. Monitoring & feedback loops
Think metrics like drift, accuracy decay, latency, and failure rates - tracked continuously.
How to Build a Scalable AI System for Business
Here’s the blueprint I use with clients when they ask how to build scalable AI systems:
Step 1 — Define the business-critical workflows
AI should serve revenue, efficiency, or customer experience. Simple.
Step 2 — Map your data sources
Structured, unstructured, third-party APIs - all must be stable.
Step 3 — Build modular pipelines
Every stage is independent and replaceable.
Step 4 — Select your infrastructure (cloud or hybrid)
We’ll get into this soon.
Step 5 — Implement CI/CD for ML
Automated testing and deployment.
Step 6 — Build observability early
If you're not monitoring, you're guessing.
Choosing the Right Infrastructure
Cloud vs On-Premise
Cloud is better for:
Fast experiments
Scaling GPU clusters
Multi-region workloads
Cost flexibility
On-prem makes sense for:
Extreme privacy requirements
Predictable workloads
Long-term cost optimization
GPU, CPU, Hybrid Scaling
Not every task needs a GPU. (Yes, I’ve seen companies burn money because every little process sat on a GPU.)
Kubernetes, Docker, Serverless
Kubernetes handles large AI workloads with resilience. Serverless is great for sporadic inference.
MLOps: The Backbone of Scalable AI
When people ask me how to scale AI in business, this is the part they miss.
What MLOps solves
Model drift
Version chaos
Training inconsistencies
Deployment failures
CI/CD for ML
Tests that check:
Data schema
Model accuracy
Inference latency
Then automated push to production.
Automated retraining
Trigger-based retraining based on:
Data volumes
Performance thresholds
Seasonal patterns
Model governance
Shapes compliance, privacy, audits - the unglamorous work that actually keeps AI reliable.
Data Strategy for Scalability
Data quality
Scaling low-quality data is like pouring more water into a leaking bucket.
Storage strategy
Object stores + lakehouses give you flexibility and speed.
Real-time vs batch
Real-time when the business needs real-time. Batch when speed doesn’t matter.
Data warehouses and lakehouses
Great for enterprise-grade AI and data pipelines for AI systems.
Deployment Strategies for Scalable AI
API-based deployment
Ideal for most AI implementations.
Edge AI deployment
Useful for low-latency environments like manufacturing.
Multi-region scalability
Necessary for global apps.
Load balancing
Critical for predictable inference performance.
Monitoring, Optimization & Cost Control
Model drift detection
No monitoring = degrading accuracy.
Resource management
Scale up for peak hours, scale down when silent.
Reducing cloud costs
Right-size GPU resources. Use spot or preemptible instances.
A/B testing for models
My go-to strategy for rolling out new models without chaos.
Common Challenges & How to Avoid Them
Scaling too early
Wrong infrastructure choices
Poor data governance
Lack of monitoring
Over-engineered pipelines
No rollback processes
No ownership
A scalable system is predictable. Predictability comes from discipline, not fancy frameworks.
Conclusion
I’ve built scalable machine learning systems that survived million-user spikes and I’ve watched others crumble under simple input changes. The difference is always architecture, clarity, and consistency.
If your business plans to invest in AI development for business, building enterprise-grade AI infrastructure is not optional. It’s the foundation for any serious AI implementation for business.
Whether you’re evaluating scalable AI infrastructure, designing scalable AI architecture, or trying to expand your business AI solutions, treat scaling as a mindset, not a phase.
Also, if you ever need conversational automation, the Best AI Voice Agent Solutions or modern AI Chatbots can sit flawlessly inside the same architecture you build here. And yes, if your team lacks engineers, you can always Hire AI Developer support to do the heavy lifting.
FAQs
Its ability to handle growth - data, traffic, features - without reducing performance or skyrocketing cost.
Costs vary widely based on data volume, infrastructure, and complexity, but planning scalability early prevents expensive rework later.
Not full scalability, but foundational decisions (pipelines, modularity, versioning) must be scalable.
Kubernetes, MLflow, Airflow, Kubeflow, Docker, and modern data orchestration frameworks.
Cloud is usually faster to start, while on-premise can be cheaper long-term for predictable workloads.
Founder & CEO
Divyang Mandani is the CEO of KriraAI, driving innovative AI and IT solutions with a focus on transformative technology, ethical AI, and impactful digital strategies for businesses worldwide.