AI Solutions for Solar Energy: How KriraAI Cut Downtime by 34%

When our team first visited the client's 340 MW solar installation outside Jodhpur in early 2024, the operations manager pulled up a spreadsheet that tracked maintenance tickets across their fleet. There were 11,400 open items — some dating back nine months. This was not a company that lacked resources or discipline. This was a leading solar energy enterprise operating over 2.1 GW of installed capacity across fourteen utility-scale sites in Rajasthan, Gujarat, Tamil Nadu, and Karnataka, employing over 300 field technicians and running a 24/7 network operations centre. The problem was not effort. The problem was that the volume of data produced by modern solar infrastructure had completely outpaced every manual and rule-based system they had built to manage it. They were generating 4.2 million telemetry data points per day from inverters, string monitors, pyranometers, and weather stations — and acting on less than 3% of that data in any meaningful way. The rest disappeared into log files that no one had time to read. This blog tells the story of the AI solutions for solar energy that KriraAI designed, built, and deployed across that entire fleet — a system that turned those 4.2 million daily signals into automated decisions, predicted failures before they happened, and delivered a 34% reduction in unplanned downtime within eight months of going live. It covers the problem in full operational detail, the architecture we built to solve it, the implementation journey including the real challenges we encountered, and the measured results the client achieved after deployment.
The Problem KriraAI Was Called In To Solve
The client's operational reality was one that most solar fleet operators above 500 MW will recognise immediately. Their fourteen sites had been commissioned over a six-year period by four different EPC contractors, each of whom had installed different inverter brands, different string monitoring hardware, and different SCADA platforms. The result was a fragmented data landscape where no single system could give a unified view of fleet health. Operations teams at each site ran their own maintenance schedules, inspection protocols, and defect tracking methods. There was no standardised way to compare the performance of one site against another, let alone one string against another.
Manual Inspections That Could Not Keep Up
Panel inspections were conducted quarterly using handheld thermal cameras and visual walkthroughs. A single 340 MW site contained approximately 780,000 individual panels arranged across 12,000 strings. A team of eight technicians needed 22 working days to complete one full thermal inspection cycle. By the time they finished, the defects discovered during the first week had already been causing energy losses for three weeks before a work order was even raised. The backlog was structural — not because the team was slow, but because manual inspection at that scale was physically impossible to keep current.
Soiling losses cost the client between 4% and 7% of annual generation depending on site location. Cleaning crews followed fixed ten-day schedules regardless of actual soiling conditions. Some rows were cleaned when they did not need it. Others were left dirty past the point where energy loss exceeded the cleaning cost. The cleaning budget ran to over 14 crore rupees annually, and at least 30% of those cycles were either premature or too late.
Yield Forecasting That Missed the Mark
The client had contractual obligations under multiple power purchase agreements requiring day-ahead generation forecasts to state load dispatch centres. Their statistical model, built on three years of historical irradiance data, produced a mean absolute percentage error of around 18%. Every megawatt-hour of over-forecasting resulted in deviation charges. Every megawatt-hour of under-forecasting left revenue uncaptured. Forecast inaccuracy was costing roughly 8.5 crore rupees per year in deviation penalties and missed spot market revenue.
Inverter Failures That Arrived Without Warning
Inverter downtime was the single largest contributor to energy losses. The fleet ran over 1,800 inverters from three manufacturers. The existing threshold-based alerting system only triggered when output had already dropped below expected power — by which point failure had occurred. The client's data showed a 6.3-day average gap between degradation onset and the threshold alert firing. During those 6.3 days, the inverter was underperforming and moving toward a hard failure requiring full replacement. Every hour of unplanned central inverter downtime cost an estimated 42,000 rupees in lost generation.
What KriraAI Built: AI Solutions for Solar Fleet Intelligence
KriraAI designed and delivered a platform we internally named SolarMind — a unified AI system that ingests the full telemetry, imagery, and environmental data stream from the client's entire fleet and transforms it into three categories of actionable intelligence: predictive maintenance alerts, optimised energy yield forecasts, and automated operational recommendations. The system was not a dashboard bolted onto existing SCADA. It was a purpose-built platform sitting alongside the client's operational infrastructure, consuming every data stream those systems produce and generating decisions that flow back into CMMS, dispatch, and grid reporting workflows.
Predictive Maintenance Engine
The predictive maintenance module operates on two parallel data channels. The first processes inverter and string-level telemetry in near-real-time — current, voltage, power, temperature, and frequency sampled at five-second intervals. KriraAI trained a temporal convolutional network combined with a variational autoencoder on eighteen months of labelled historical fault data to build a degradation signature library for each inverter type. The model identifies subtle patterns — gradual capacitor degradation, IGBT thermal drift, fan bearing wear — that precede failures by an average of 11.4 days.
The second channel processes drone-captured thermal and electroluminescence imagery. KriraAI fine-tuned an EfficientNet-V2 backbone with a feature pyramid network for multi-scale defect detection, trained on 94,000 labelled panel images covering hotspots, microcracks, potential-induced degradation, snail trails, delamination, and junction box failures. The model achieves 91.3% mean average precision at IoU 0.5. Drone flights previously requiring 22 days of manual analysis are now processed in under four hours, with defects georeferenced and linked to the correct asset.
Yield Forecasting and Soiling Intelligence
The yield forecasting module uses a Temporal Fusion Transformer that fuses satellite-derived irradiance forecasts, ground-level pyranometer readings, numerical weather prediction data, panel degradation state, soiling estimates, and curtailment schedules. The model generates probabilistic forecasts at 15-minute granularity with uncertainty quantification, reducing MAPE from 18% to 6.2% day-ahead and 3.8% on a four-hour horizon. The soiling module uses a gradient-boosted ensemble to predict daily soiling accumulation at the string level, outputting a cleaning priority map ranked by ROI of cleaning per zone. This replaced the fixed schedule with dynamic, data-driven dispatch.
Solution Architecture: Layer by Layer
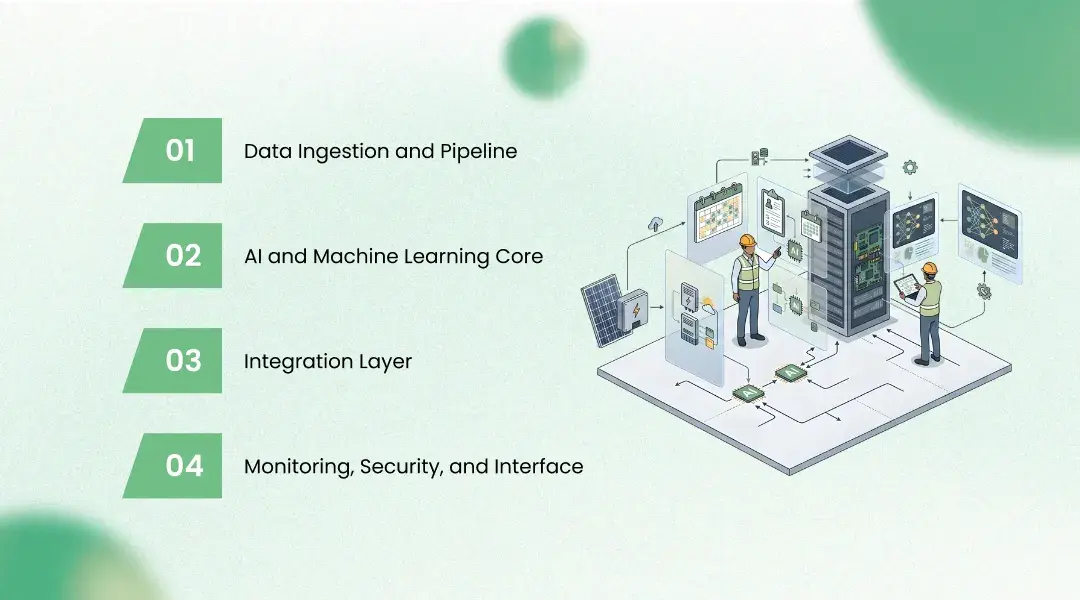
Data Ingestion and Pipeline
The pipeline ingests telemetry from 1,800 inverters and 48,000 string monitors via MQTT brokers at each site, feeding into Apache Kafka on AWS MSK with six brokers partitioned by site and data type. Drone imagery lands in S3 buckets via automated upload from DJI FlightHub, triggering Lambda functions for processing queue registration. Weather and irradiance data is pulled on fifteen-minute intervals via Prefect-orchestrated extraction DAGs. Schema normalisation and temporal alignment is handled by Apache Flink stream processing jobs producing a unified time-series representation in Parquet format, landed in Delta Lake on S3. Feature engineering runs as both streaming jobs for real-time features and batch jobs for daily aggregations, with Feast serving both online and offline paths.
AI and Machine Learning Core
Training runs on AWS p4d.24xlarge instances for CV models and g5.2xlarge instances for time-series models, orchestrated by Kubeflow Pipelines on Amazon EKS with MLflow for experiment tracking and model registry. The inverter degradation model was trained with hard negative mining to discriminate between genuine degradation and benign operational transients. The EfficientNet-V2 model used two-stage transfer learning — first domain adaptation on a public defect dataset, then fine-tuning on proprietary imagery with focal loss for class imbalance. The Temporal Fusion Transformer was trained with quantile loss producing calibrated prediction intervals at the 10th, 50th, and 90th percentiles. Production serving uses TensorRT-optimised containers for CV and ONNX Runtime for time-series models behind KServe on Kubernetes with autoscaling on queue depth.
Integration Layer
Predictive maintenance alerts flow into the client's SAP Plant Maintenance via an OData REST API, automatically generating work orders with defect type, severity, affected asset, and recommended repair pre-populated. Yield forecasts reach the scheduling desk via a gRPC endpoint with sub-200ms latency. The cleaning priority map is delivered as a daily API payload to the dispatch application. All contracts are versioned in OpenAPI 3.1 with automated contract testing via Pact in CI/CD.
Monitoring, Security, and Interface
Infrastructure metrics — container CPU, memory, GPU utilisation, inference latency at p50, p95, and p99 — are collected by Prometheus and visualised in Grafana. Model performance monitoring runs as a Flink job comparing predictions against actuals. A population stability index monitor triggers Slack alerts when PSI exceeds 0.2 on any input feature. A human-in-the-loop workflow samples 5% of defect predictions weekly for expert review. Automated retraining triggers when rolling 30-day mAP drops below 88% or yield MAPE exceeds 8% for five consecutive days.
The platform runs within a private VPC with no public endpoints. Data in transit uses TLS 1.3 and data at rest uses AWS KMS with customer-managed keys. Role-based access control with attribute-level data masking ensures site-level financial data visibility matches authorisation tiers. Audit logs write to immutable append-only stores with 365-day retention. The platform completed SOC 2 Type I assessment as part of vendor security requirements.
The primary interface is a React-based dashboard served through CloudFront, presenting fleet health as a hierarchical map with colour-coded risk indicators. A mobile-responsive version allows field technicians to receive work orders and close tickets from the field.
Technology Stack: Why We Chose What We Chose
Every technology was selected based on compatibility with the client's AWS-centric infrastructure, capacity to handle 2.1 GW with headroom for 5 GW growth, and maintainability by the client's in-house team after handover.
Apache Kafka on AWS MSK was chosen over Kinesis because the client required topic-level partitioning by site with configurable retention periods — capabilities Kinesis does not support with the same flexibility.
Apache Flink was chosen over Spark Structured Streaming because inverter degradation detection requires event-time windowing with late-arrival handling that Flink's watermark semantics manage more naturally.
Delta Lake was selected over Apache Iceberg because the client's data engineering team had prior Databricks experience, reducing the post-handover learning curve.
EfficientNet-V2 was selected over vision transformers for defect detection because the model needed to run on NVIDIA Jetson Orin Nano edge devices within a 4 GB VRAM constraint for future offline capability.
Temporal Fusion Transformer was chosen over N-BEATS and DeepAR because TFT natively supports multi-horizon probabilistic forecasting with interpretable attention weights that the scheduling team required.
How We Delivered It: The AI Implementation Solar Industry Journey
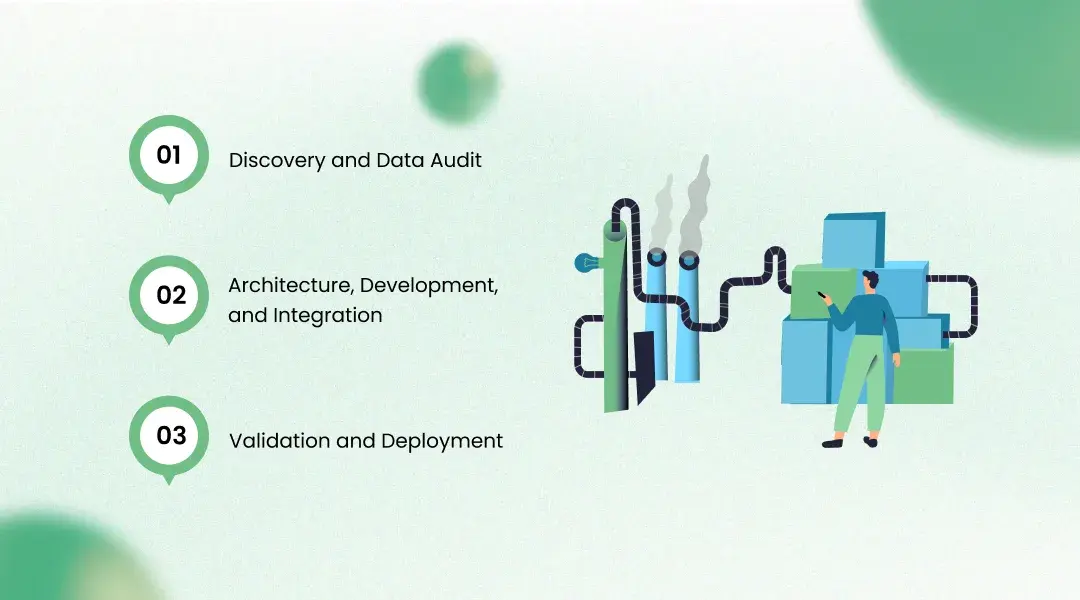
Discovery and Data Audit (Weeks 1 through 4)
KriraAI embedded a two-person team at the Jodhpur and Chennai sites for three weeks. The goal was understanding the actual state of the client's data. Inverter telemetry from two manufacturers had 8% to 12% missing data due to packet drops during network fluctuations. String monitor data from the oldest sites used legacy Modbus requiring a custom MQTT adapter. Drone imagery was stored in inconsistent folder structures with no standardised metadata. The first four weeks built a complete data inventory, quantified quality issues, and designed the pipeline to handle these realities rather than assuming clean data.
Architecture, Development, and Integration (Weeks 5 through 22)
Architecture design ran in parallel with model prototyping. The critical finding was that the inverter degradation model needed separate training per manufacturer — a single model across all three brands performed poorly because normal-operation telemetry signatures differed significantly. This tripled training workload but was essential for production accuracy.
Development deployed nine engineers — three ML, two data, two backend, one frontend, one MLOps. The most significant challenge was SAP Plant Maintenance integration. The client's heavily customised ECC 6.0 instance had custom maintenance order types that did not map to SAP's standard OData API. KriraAI worked with the client's SAP Basis team to build a custom RFC function module, consuming four weeks of engineering effort alone.
Validation and Deployment (Weeks 23 through 28)
The yield model was validated against 90 days of held-out data across all fourteen sites, benchmarked against the existing statistical model. The defect model was validated by three independent solar O&M engineers who reviewed 2,000 predictions. The predictive maintenance model was validated retrospectively against historical failure records. Deployment followed a phased rollout — three pilot sites, then regional expansion, then full fleet activation over six weeks.
Results the Client Achieved
Within eight months of full fleet deployment, the platform delivered measurable outcomes across every operational dimension.
Unplanned downtime reduced by 34% — 847 inverter degradation events identified and resolved before failure.
Yield forecast MAPE reduced from 18% to 6.2% — deviation penalty charges cut by an estimated 5.8 crore rupees annually.
Manual inspection labour reduced by 61% — machine learning solar panel inspection via drone imagery replaced quarterly full-site walkthroughs with targeted inspections.
Cleaning budget reduced by 28% — dynamic soiling intelligence eliminated unnecessary cycles while prioritising high-loss zones.
Overall fleet energy output increased by 2.8% — combined effect of fewer outages, faster remediation, and tighter yield management.
The platform achieved payback within nine months. The annualised ROI exceeded 340% when accounting for reduced penalties, lower maintenance costs, and incremental energy revenue. The client's COO noted that the single most valuable capability was the predictive maintenance engine's ability to convert reactive failures into planned maintenance events — a shift that reduced not only direct energy losses but also spare parts logistics costs and emergency contractor callout fees.
What This Architecture Makes Possible Next
The SolarMind platform was architected to scale beyond the initial deployment. The Kafka-based ingestion layer supports horizontal scaling to a fleet three times the current size without architectural changes — adding a new site requires only provisioning new MQTT topics and registering the site's asset hierarchy in the configuration service, a process that takes less than two days of engineering effort. ML models are versioned and site-parameterised — a new site's models can be initialised via transfer learning and fine-tuned on site-specific data within two weeks of commissioning.
The client's roadmap includes three extensions. First, integrating battery energy storage telemetry into the predictive maintenance pipeline — the temporal convolutional architecture generalises well to battery degradation with BESS-specific retraining. Second, adding real-time energy trading optimisation combining yield forecasts with spot market signals — the TFT's probabilistic output provides the uncertainty quantification trading algorithms require. Third, deploying edge inference on NVIDIA Jetson modules for offline drone defect detection. KriraAI has already delivered the edge-optimised model quantised to INT8 via TensorRT, achieving 14 FPS on Jetson Orin Nano with less than 1.2% mAP degradation versus full-precision cloud inference.
Conclusion
Three insights from this engagement stand out. Technically, training separate inverter degradation models per manufacturer rather than pursuing a universal model was the difference between a prototype and a production system — domain-specific architecture decisions matter more than model sophistication. Operationally, the largest gain came from unifying fragmented data streams into one platform. The client went from fourteen disconnected SCADA views to one fleet intelligence layer, and that consolidation changed daily decision-making. Strategically, the solar energy yield optimization capability transformed the client's relationship with grid operators — tighter forecasts meant fewer penalties and a measurable advantage in capacity auctions.
KriraAI brings this depth of engineering rigour — from data pipeline architecture through model training through production MLOps — to every engagement. We do not build demos or proofs of concept that stall after the first presentation. We build production systems that handle real enterprise workloads at scale and deliver measurable results within defined timelines. Every engagement draws on the same discipline: understand the data first, design for production from day one, and measure success by business outcomes rather than model accuracy in isolation. If your organisation operates at a scale where AI can turn data you already have into decisions you are not yet making, bring that challenge to KriraAI.
FAQs
AI is applied across multiple domains in utility-scale solar energy — predictive maintenance solar farms operations, energy yield forecasting, automated defect detection through drone imagery, and dynamic soiling management. In this engagement, KriraAI deployed AI solutions for solar energy combining all four capabilities into one platform. The predictive maintenance module used temporal convolutional networks to detect inverter degradation 11.4 days before failure. The defect detection module processed thermal imagery with 91.3% mean average precision. The yield forecasting module reduced day-ahead error from 18% to 6.2%. These are production systems processing 4.2 million data points daily across a 2.1 GW fleet, not theoretical applications.
The return on investment depends on fleet size, operational maturity, and use cases deployed. In this engagement, the client achieved an annualised ROI exceeding 340% within nine months. The largest contributors were the 34% reduction in unplanned downtime, which preserved generation revenue, and improved yield forecast accuracy, which reduced deviation penalties by approximately 5.8 crore rupees annually. Cleaning optimisation contributed a 28% budget reduction. Solar companies above 500 MW with existing telemetry infrastructure are best positioned because the marginal cost of AI deployment decreases with scale while the absolute value of percentage improvements in output grows proportionally.
Computer vision detects defects by analysing thermal and electroluminescence drone imagery. In the system KriraAI built, the machine learning solar panel inspection module uses an EfficientNet-V2 backbone with a feature pyramid network processing images at multiple scales. The model was trained on 94,000 labelled images covering hotspots, microcracks, potential-induced degradation, snail trails, delamination, and junction box failures. Each detected defect is georeferenced using drone GPS telemetry and linked to the correct string and inverter in the asset management system, enabling technicians to navigate directly to the affected panel without separate inspection.
Predictive maintenance for solar farms uses machine learning to predict equipment failures before they occur, enabling preventive repair rather than reactive replacement. Unlike threshold-based alerting that triggers only after performance has degraded, predictive maintenance solar farms systems detect subtle early degradation patterns. The KriraAI system analyses inverter telemetry sampled at five-second intervals. A temporal convolutional network identifies signatures like capacitor degradation, IGBT thermal drift, and fan bearing wear by comparing real-time patterns against a learned pre-failure library. The system provided 11.4 days average lead time, compared to the previous 6.3-day lag between degradation onset and threshold alert.
The timeline depends on data infrastructure complexity, integration points, and scope. KriraAI completed this AI implementation solar industry project in 28 weeks from kickoff to full fleet deployment. Data audit and pipeline design consumed four weeks — a phase often underestimated but critical since telemetry quality directly determines model performance. Architecture design and prototyping took six weeks. Development and integration required twelve weeks, with SAP integration being the most intensive workstream. Validation and phased deployment took six weeks. Solar companies should budget six to eight months for production deployment covering multiple use cases.
Founder & CEO
Divyang Mandani is the CEO of KriraAI, driving innovative AI and IT solutions with a focus on transformative technology, ethical AI, and impactful digital strategies for businesses worldwide.