AI-Powered Threat Detection: How KriraAI Built a Security Operations Platform
Every 24 hours, the security operations center of one of our enterprise security clients generated over 14,000 alerts. Analysts worked in rotating shifts, triaging each event manually, correlating indicators across siloed dashboards, and making judgment calls about severity under constant time pressure. On an average weekday, fewer than 23% of those alerts received meaningful human analysis within the first hour. The rest queued, aged, and in many cases expired without review. It was not a staffing problem. It was a structural one. The volume of telemetry flowing into the SOC had long exceeded the capacity of any team to process it with the tools they had.
When KriraAI began this engagement, the client's leadership had already invested significantly in conventional SIEM platforms, signature-based detection rules, and a growing headcount of Tier 1 analysts. The gap between investment and outcome was widening. Dwell time for genuine threats averaged 17 days. False positive rates across their detection rules sat at 87%. The cost per investigated incident had climbed to over $142, and the majority of that cost was consumed by triage work that ultimately concluded the alert was benign.
This blog walks through the complete AI-powered threat detection platform that KriraAI's custom AI software development team designed, built, and deployed for this client. It covers the operational crisis that prompted the engagement, the technical architecture we delivered, the implementation challenges we solved along the way, and the measurable results the client achieved within the first six months of production operation.
The Problem KriraAI Was Called In To Solve
The client operated a mature security operations center supporting a distributed enterprise environment with over 40,000 endpoints, 12,000 cloud workloads across AWS and Azure, and a hybrid network spanning seven geographic regions. Their telemetry stack included endpoint detection and response agents, network flow analyzers, CloudTrail logs, identity provider event streams, email gateway logs, and web proxy records. The total daily log volume exceeded 4.2 terabytes. Their existing SIEM ingested this data and applied approximately 3,800 correlation rules, many of which had been written years earlier and never tuned for the client's evolving environment.
The Alert Fatigue Crisis
The most immediate and damaging consequence was alert fatigue. Tier 1 analysts were expected to triage between 350 and 500 alerts per shift. The workflow for each alert involved opening a ticket, pulling contextual data from three to five different tools, checking asset inventories and user directories, evaluating whether the activity matched known threat patterns, and writing a brief disposition note before closing or escalating. Each triage cycle took between 18 and 45 minutes, depending on complexity. Analysts developed personal shortcuts and heuristics that were never documented, never standardized, and often contradictory between shifts. When a genuinely malicious event appeared in the queue, it looked no different from the thousands of false positives surrounding it. There was no systematic way to prioritize what mattered.
The detection rules themselves compounded the problem. Many had been created in response to specific past incidents and were never retired even after the threat landscape shifted. Others were overly broad, triggering on common administrative actions that happened to match suspicious patterns. A rule designed to catch lateral movement via SMB, for example, fired every time a network printer driver was updated across the fleet. Analysts knew which rules to mentally deprioritize, but that knowledge existed only in their heads. New hires took months to develop the same intuitions, and turnover in the SOC was running above 30% annually.
Data Existed but Was Not Connected
The client had invested in excellent telemetry coverage. Their EDR platform captured process execution trees, file system changes, registry modifications, and network connections at the endpoint level. Their cloud security posture management tool flagged misconfigurations and anomalous API calls. Their identity provider logged every authentication event, every privilege escalation, and every session anomaly. The problem was that none of these data sources were connected in a way that allowed an analyst to see a complete attack narrative. Each tool presented its own view. Correlating a suspicious login from an unfamiliar location with a subsequent cloud API call that provisioned a new IAM role and then a lateral movement attempt on the internal network required an analyst to manually query four different systems, align timestamps, and build the story themselves. Most of the time, they did not have the time to do it.
The Cost of the Status Quo
The financial burden was significant. The SOC was running an annual operational budget exceeding $8.6 million, with roughly 62% allocated to personnel costs for analyst headcount that was still insufficient for the workload. Incident response retainer costs with external firms added another $1.2 million annually because the internal team could not investigate complex incidents fast enough. The client estimated that the mean time to detect a genuine compromise was 17 days and the mean time to contain it after detection was another 4.3 days. Industry benchmarks for their sector, closely mirrored in KriraAI's work addressing finance industry compliance needs, suggested that each day of undetected compromise carried a potential financial exposure of $46,000 in data exfiltration risk, regulatory penalty probability, and remediation cost escalation. The leadership team understood that improving headcount alone would never solve the problem. They needed a fundamentally different approach.
What KriraAI Built: An Autonomous Threat Detection and Triage Platform
KriraAI designed and delivered a production AI platform that replaced the manual alert triage workflow entirely for Tier 1 operations and augmented Tier 2 and Tier 3 investigation with automated evidence assembly and threat narrative generation. The system ingests the client's full telemetry stream in real time, applies multi-stage AI analysis to every event, and produces contextualized, prioritized incident packages that are ready for human decision-making the moment they surface.
The Core Intelligence Pipeline
At the heart of the platform is a multi-model inference pipeline. The first stage applies an ensemble of anomaly detection models trained on the client's own baseline telemetry. These models use temporal convolutional networks to capture sequential patterns in endpoint behavior and variational autoencoders to learn the normal distribution of network flow characteristics across the client's specific environment. Every event that deviates from baseline beyond a calibrated threshold proceeds to the second stage.
The second stage performs entity-centric threat scoring using a graph neural network. This GNN operates on a continuously updated knowledge graph that represents relationships between users, devices, IP addresses, cloud resources, applications, and known threat indicators. When the anomaly detection stage flags an event, the GNN evaluates it in the context of the entity's recent behavioral history, its relationships to other flagged entities, and its proximity to known attack patterns encoded in the graph. This contextual scoring is what eliminates the false positive problem. An SMB connection from a printer update and an SMB connection from a compromised workstation attempting lateral movement produce entirely different graph signatures, even though they trigger the same legacy correlation rule.
The third stage generates a human-readable threat narrative for every incident that crosses the scoring threshold. KriraAI built this capability using a retrieval-augmented generation pipeline backed by a fine-tuned large language model. The RAG system retrieves relevant context from the client's historical incident database, their asset inventory, their vulnerability scan results, and curated threat intelligence feeds. The language model then synthesizes this context into a structured incident report that includes a plain-language description of what happened, a timeline of the attack chain, a severity assessment with supporting evidence, and recommended containment actions. This is the report that Tier 2 analysts see when they open an incident. Before KriraAI's platform, building this report manually took between 2 and 4 hours. The system produces it in under 90 seconds.
Solution Architecture: A Technical Deep Dive into AI-Powered Threat Detection
The architecture was designed as a series of loosely coupled, independently scalable services deployed within the client's existing private cloud environment with no data leaving their network boundary.
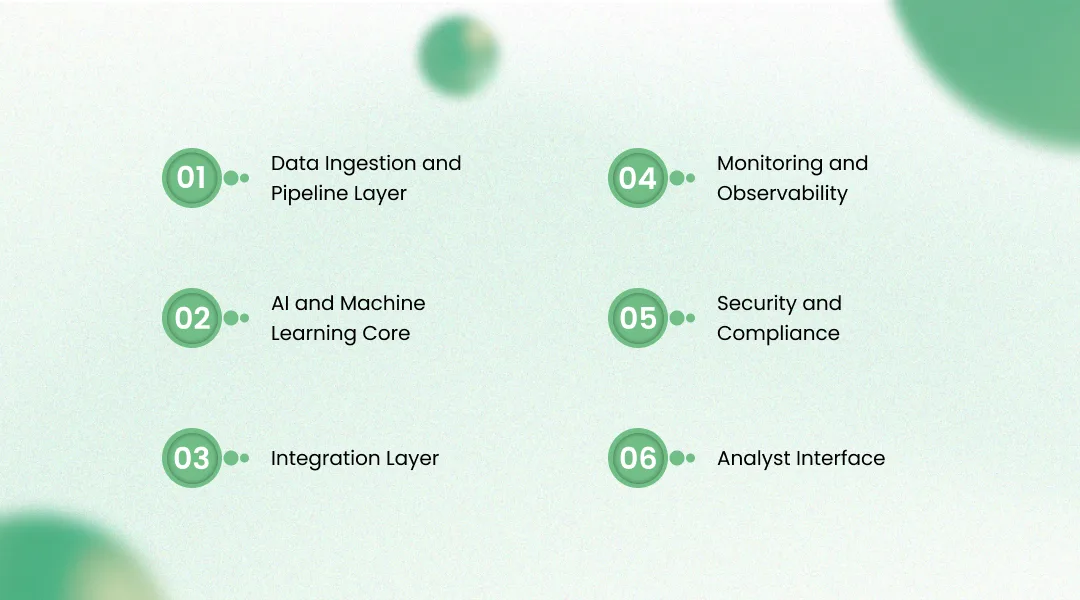
Data Ingestion and Pipeline Layer
Telemetry from all sources flows into a centralized event streaming platform built on Apache Kafka. KriraAI deployed a Kafka cluster with 24 brokers partitioned by source type, providing sustained ingestion throughput above 2.8 million events per second during peak hours. Each source type has a dedicated connector: Filebeat and Elastic Agent for endpoint telemetry, custom Kafka Connect connectors for CloudTrail logs pulled via change data capture patterns, syslog receivers for network devices, and webhook listeners for identity provider events.
Raw events pass through a stream processing layer built on Apache Flink. The Flink jobs perform schema normalization across all source types into a unified event schema, entity resolution to map disparate identifiers (hostname, IP, user principal name, device ID) to canonical entity records in the knowledge graph, and temporal feature engineering that computes rolling statistical features such as event frequency, entropy of destination addresses, and time-since-last-activity for each entity. Flink also generates vector embeddings for each event at ingestion time using a lightweight sentence transformer model deployed as a sidecar service, enabling downstream similarity search and clustering. Processed events land in two destinations: Apache Pinot for real-time analytical queries powering the analyst dashboard, and an object store (MinIO) in Parquet format for batch model retraining.
AI and Machine Learning Core
The anomaly detection ensemble runs as a set of stateless inference services behind an internal gRPC API. Each model is served using NVIDIA Triton Inference Server with TensorRT optimization, achieving p99 inference latency below 12 milliseconds per event on NVIDIA A10G GPUs. The temporal convolutional network and variational autoencoder models were trained using PyTorch on the client's historical telemetry spanning 14 months, with supervised fine-tuning on a curated dataset of 2,300 confirmed security incidents labeled by the client's senior analysts.
The graph neural network is implemented using PyTorch Geometric and operates on a property graph stored in Neo4j, the same graph-based contextual scoring approach detailed in our AI in telecom network operations case study, where it cut mean time to repair by 72%. The graph updates continuously as new events arrive, with entity nodes and relationship edges reflecting the latest state of the environment. The GNN uses a GraphSAGE architecture with three aggregation layers, which KriraAI selected for its ability to perform inductive inference on previously unseen nodes without requiring full graph retraining. The model was trained using a contrastive learning objective, where positive pairs were entities involved in confirmed incidents and negative pairs were entities from benign activity windows.
The RAG pipeline for narrative generation uses a vector index built on Milvus with HNSW indexing, containing embeddings of historical incident reports, MITRE ATT&CK technique descriptions, and threat intelligence bulletins. The retriever fetches the top 12 most relevant context passages per incident. The generator is a Mistral-7B model fine-tuned on 8,400 analyst-written incident reports using supervised fine-tuning with LoRA adapters, served via vLLM with continuous batching enabled to handle concurrent generation requests without queuing.
Integration Layer
The platform integrates bidirectionally with the client's existing ITSM platform (ServiceNow) and their SOAR platform (Palo Alto XSOAR) through event-driven integration patterns. When the AI pipeline produces a scored and narrated incident, it publishes the incident package to a dedicated Kafka topic. A set of integration microservices consumes from this topic and executes the appropriate downstream actions: creating a ServiceNow incident ticket with pre-populated fields, triggering a SOAR playbook for automated containment actions on high-confidence threats, and pushing enrichment data back into the SIEM for analyst visibility. All integration services expose versioned REST APIs documented in the OpenAPI 3.1 specification, enabling the client's internal engineering team to build additional integrations independently. For latency-sensitive internal service communication between the inference pipeline and the integration layer, KriraAI used gRPC with Protocol Buffers, achieving round-trip communication times below 4 milliseconds within the cluster.
Monitoring and Observability
KriraAI deployed a comprehensive MLOps monitoring stack. Data drift detection runs continuously, comparing incoming feature distributions against training baselines using the population stability index for categorical features and Kolmogorov-Smirnov tests for continuous features. When PSI exceeds 0.2 for any feature, the system triggers a drift alert and queues the affected model for evaluation against a held-out test set. Model performance is tracked against a rolling evaluation set maintained by the client's Tier 3 team, who label a random 2% sample of incidents weekly. Precision, recall, and F1 scores are computed daily and visualized in a Grafana dashboard alongside infrastructure metrics. Latency tracking covers p50, p95, and p99 for every inference endpoint and integration service, with PagerDuty alerts configured for p99 breaches above defined thresholds. An automated retraining pipeline built on Kubeflow Pipelines triggers when the F1 score drops below 0.91 for any model, executing a full retrain cycle with automatic validation and canary deployment.
Security and Compliance
Because the platform processes the client's most sensitive security telemetry, KriraAI implemented defense-in-depth security controls throughout. All data in transit uses mutual TLS. Data at rest in MinIO and Neo4j uses AES-256 encryption with keys managed in HashiCorp Vault. Role-based access control with attribute-level data masking ensures that analysts see only the telemetry relevant to their assigned scope. All API calls, model inference requests, and administrative actions are logged to an immutable append-only audit store backed by Amazon S3 Object Lock with governance mode retention. The entire platform runs in a private VPC with no public endpoints, and all inter-service communication occurs over a service mesh (Istio) with strict mTLS enforcement and network policies restricting lateral communication to only explicitly authorized service pairs. The deployment satisfies the client's SOC 2 Type II and ISO 27001 compliance requirements.
Analyst Interface
The delivery mechanism for AI outputs is a custom web application built in React with a FastAPI backend. The interface presents a prioritized incident queue where each incident includes the AI-generated threat narrative, an interactive attack chain visualization rendered as a directed acyclic graph, the entity risk scores from the GNN, and one-click actions to approve containment playbooks or escalate to Tier 3. The interface also includes a feedback mechanism where analysts can confirm or correct the AI's assessment, and this feedback flows directly into the labeling pipeline for continuous model improvement.
Technology Stack: Why Every Choice Was Deliberate
The technology decisions KriraAI made for this engagement were driven by three constraints: the system had to run entirely within the client's private infrastructure, it had to handle sustained throughput above 2.5 million events per second, and it had to integrate with an existing technology estate that included ServiceNow, Palo Alto XSOAR, Splunk, and CrowdStrike Falcon.
Apache Kafka was chosen over Amazon Kinesis because the client required an on-premises deployment with no cloud-managed service dependencies for their security telemetry pipeline.
Apache Flink was selected over Spark Structured Streaming for its true event-time processing semantics and lower latency at the sustained throughput required.
Neo4j was chosen for the knowledge graph over Amazon Neptune because of its mature Cypher query language, its strong support for dynamic graph updates, and the client's team's familiarity with the platform.
NVIDIA Triton Inference Server was selected for model serving because it natively supports concurrent model execution across multiple frameworks (PyTorch, TensorRT, ONNX) on the same GPU pool, maximizing hardware utilization.
Milvus was chosen as the vector database over Pinecone because the client required a self-hosted solution with no external API dependencies, and Milvus offered the HNSW indexing performance needed for sub-10ms retrieval at the embedding volume we projected.
vLLM was selected for LLM serving due to its PagedAttention mechanism, which delivered 3.2x higher throughput than standard Hugging Face serving on the same hardware during our benchmarks.
Kubeflow Pipelines was selected for ML workflow orchestration because the client's infrastructure team already operated Kubernetes clusters and preferred a Kubernetes-native solution over standalone orchestrators like Airflow for ML-specific workloads.
How We Delivered It: The Implementation Journey
The engagement spanned 28 weeks from kickoff to production go-live, structured in six phases.
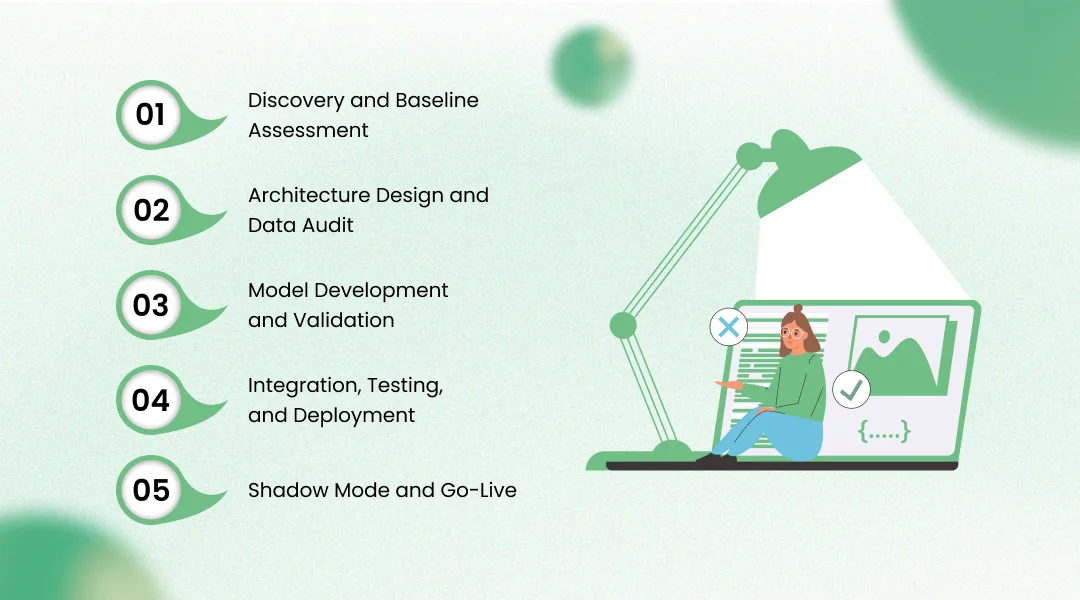
Discovery and Baseline Assessment (Weeks 1 to 4)
KriraAI embedded a two-person team in the client's SOC for three weeks. The goal was not to observe from a distance but to sit alongside analysts, handle the same queues, and understand the operational reality at the workstation level. During this phase, we cataloged every data source, every detection rule, every triage workflow, and every integration point. We also established baseline performance metrics: mean triage time per alert (26 minutes), false positive rate (87%), mean time to detect (17 days), and mean time to contain (4.3 days). These baselines became the scorecard against which every subsequent decision was measured.
Architecture Design and Data Audit (Weeks 5 to 8)
The architecture design phase surfaced the first major challenge. The client's endpoint telemetry had inconsistent timestamp precision across geographic regions, with some agents reporting in UTC and others in local time with ambiguous offset handling. Temporal feature engineering depends on accurate and consistent timestamps. KriraAI built a timestamp normalization service as the first component of the Flink pipeline, applying heuristic correction for known agent versions and flagging events with unresolvable timestamp conflicts for manual review. We also discovered that the client's historical incident labels were incomplete: only 41% of closed incidents in their ITSM system had a root cause classification detailed enough to use as training labels. KriraAI's data engineering team spent two weeks working with the client's senior analysts to relabel 14 months of incident history, producing the 2,300-incident training corpus that became the foundation for supervised fine-tuning.
Model Development and Validation (Weeks 9 to 16)
Model development proceeded in parallel tracks. The anomaly detection ensemble required the most iterations. The initial variational autoencoder produced a reconstruction error distribution that was too broad, generating excessive false anomalies on Monday mornings when user behavior patterns shifted from weekend baselines. KriraAI resolved this by introducing day-of-week and time-of-day conditioning variables into the encoder, allowing the model to learn distinct behavioral baselines for different temporal contexts. The GNN training presented a class imbalance challenge: genuine security incidents represented less than 0.3% of the training graph. We applied a combination of focal loss and neighborhood sampling strategies to ensure the model learned meaningful representations for both benign and malicious subgraphs.
Integration, Testing, and Deployment (Weeks 17 to 24)
Integration with ServiceNow and XSOAR required careful coordination with the client's IT operations team. The ServiceNow integration needed to respect existing approval workflows and SLA timers that the client had configured over several years. KriraAI built the integration as an event consumer that creates incident records using ServiceNow's Table API, mapping AI-generated severity scores to the client's existing priority matrix. The SOAR integration was more complex: we had to ensure that automated containment actions triggered by high-confidence AI assessments included safeguards to prevent disruption to business-critical systems. KriraAI implemented a protected asset registry that the AI system checks before recommending any containment action, preventing automated isolation of assets flagged as business-critical by the client's operations team.
Shadow Mode and Go-Live (Weeks 25 to 28)
The platform ran in shadow mode for four weeks, processing the full telemetry stream and producing incident packages in parallel with the existing manual workflow. During shadow mode, the client's Tier 3 team reviewed every AI-generated incident alongside the corresponding manual triage result. This phase identified 14 edge cases where the AI's assessment diverged from analyst judgment, each of which was traced to a specific gap in the training data or a feature engineering assumption that did not hold for the client's environment. KriraAI corrected each case, retrained the affected models, and validated the fixes before go-live. Production cutover happened on a Monday morning with the KriraAI team on-site, and the system processed its first 24 hours of live production telemetry without a single escalation to the fallback manual workflow.
Results the Client Achieved
The metrics after six months of production operation validated the investment decisively.
Mean triage time per alert dropped from 26 minutes to 2.3 minutes (91% reduction), with the AI handling initial triage autonomously and presenting analysts with pre-investigated incident packages.
False positive rate decreased from 87% to 4.2%, eliminating the alert fatigue that had plagued the SOC for years.
Mean time to detect improved from 17 days to 14 hours, a 96.6% reduction driven by the system's ability to correlate weak signals across data sources in real time rather than waiting for a single high-confidence alert.
Mean time to contain dropped from 4.3 days to 3.1 hours because containment playbooks now execute automatically upon analyst approval of AI-recommended actions.
Cost per investigated incident fell from $142 to $31, a 78% reduction.
Analyst headcount reallocation: 12 Tier 1 analyst positions were redeployed to Tier 2 investigation and proactive threat hunting roles, increasing the team's capacity for complex analysis without any reduction in workforce.
The client's CISO reported that the platform identified and contained two genuine advanced persistent threat campaigns within the first 90 days that the previous system had missed entirely during its initial reconnaissance phases.
What This Architecture Makes Possible Next
The platform was designed from the outset as a foundation, not a point solution. The knowledge graph and entity scoring architecture can accommodate new data source types without modification to the core inference pipeline. The client is currently onboarding operational technology (OT) telemetry from their industrial control systems, which will extend AI-powered threat detection into environments that were previously monitored only by signature-based rules with no contextual intelligence.
The RAG pipeline for threat narrative generation can be extended to support automated regulatory reporting. By adding retrieval sources for regulatory frameworks and reporting templates, the system can draft compliance notifications (such as GDPR breach reports or SEC incident disclosures) within minutes of incident confirmation. KriraAI designed the RAG architecture with pluggable retrieval sources specifically to support this kind of extension without rebuilding the generation layer.
The GNN-based entity scoring model also opens a pathway toward predictive security posture assessment. By analyzing the graph structure of entity relationships and behavioral patterns, the system can identify entities that are accumulating risk factors consistent with pre-attack conditions, enabling proactive hardening before an attack materializes. The client has included this capability in their 18-month AI roadmap, and the foundational infrastructure to support it is already in production. Other security organizations facing similar scale challenges can apply the same architectural patterns, particularly the combination of streaming anomaly detection with graph-based contextual scoring, to transform their own SOC operations from reactive alert processing to proactive threat intelligence.
Conclusion
Three insights from this engagement stand out above the rest. First, the technical insight: contextual scoring through graph neural networks is the single most impactful architectural decision for reducing false positives in security operations, because it transforms isolated alerts into connected threat narratives that analysts can evaluate in seconds rather than hours. Second, the operational insight: the data preparation and labeling phase is where most enterprise AI projects succeed or fail, and organizations that invest in properly labeling their historical incident data create a training foundation that compounds in value with every retraining cycle. Third, the strategic insight: building an AI security platform as a modular, extensible architecture rather than a monolithic product ensures that the investment grows in value as new data sources, new use cases, and new threat categories emerge over time.
KriraAI brings this same depth of engineering rigour and delivery discipline to every client engagement, whether the challenge involves security operations, operational intelligence, or any domain where AI can transform how organizations process information and make decisions. Our team designs production systems, not proof-of-concept demonstrations, and we measure success by the operational outcomes our clients achieve after go-live, not by the sophistication of the models in isolation. If your organization is facing an AI challenge that demands genuine engineering depth and a team that has delivered at this level before, we would welcome the conversation.
FAQs
AI-powered threat detection reduces false positives by moving beyond static signature matching to contextual behavioral analysis. Traditional detection rules trigger on pattern matches without understanding whether the matched activity is normal for the specific user, device, or environment. An AI system trained on an organization's own telemetry baseline learns what normal behavior looks like for each entity and only flags deviations that are genuinely anomalous in context. In the system KriraAI built, the graph neural network adds a second layer of contextual filtering by evaluating each anomaly in the context of the entity's relationships and recent activity history. This dual-stage approach is what drove the false positive rate from 87% down to 4.2%, because the AI evaluates what happened and also evaluates who did it, from where, at what time, and in relation to what other activity.
A production-grade enterprise security AI implementation typically requires between 24 and 32 weeks from kickoff to go-live, depending on the complexity of the existing telemetry environment and the quality of historical incident data available for model training. The KriraAI engagement described in this case study took 28 weeks, with the most time-intensive phases being data preparation and labeling (which consumed approximately five weeks) and model development and validation (which consumed eight weeks). Organizations with well-labeled historical incident data and consistent telemetry schemas can compress these phases. The shadow mode validation period, typically three to four weeks, should never be shortened because it is the phase where edge cases are identified and corrected before the system handles production decisions.
The most effective approach for AI-driven incident response combines multiple model types rather than relying on a single architecture. Anomaly detection benefits from temporal models like temporal convolutional networks or LSTMs that capture sequential patterns in event streams. Contextual scoring benefits from graph neural networks that can evaluate entities and their relationships within the network topology. Threat narrative generation benefits from retrieval augmented generation pipelines using fine-tuned large language models. KriraAI's architecture uses all three in a staged pipeline, where each model type handles the task it is best suited for. Attempting to solve all three tasks with a single model architecture typically produces inferior results because the tasks require fundamentally different representations of the data.
Yes, and in most enterprise environments, augmenting rather than replacing existing SIEM and SOAR investments is the correct architectural decision. The AI platform KriraAI delivered integrates with the client's existing Splunk SIEM and Palo Alto XSOAR through event-driven patterns using Kafka as the integration backbone. The SIEM continues to perform log aggregation and compliance reporting, while the AI platform handles intelligent triage and contextual analysis. The SOAR platform continues to execute containment and remediation playbooks, but now receives pre-investigated incident packages from the AI system rather than raw alerts. This integration approach protects the client's existing investment, preserves workflows that analysts are already trained on, and adds AI intelligence as a layer rather than demanding a complete tooling replacement.
Deploying AI in a security operations environment demands the highest tier of security controls because the AI system processes the organization's most sensitive telemetry data and, in some configurations, has the ability to trigger containment actions that affect production systems. At minimum, the deployment requires end-to-end encryption for data in transit and at rest, role-based access control with attribute-level masking to limit analyst visibility to their authorized scope, immutable audit logging of all AI decisions and actions, and deployment within a private network boundary with no public endpoints. The KriraAI deployment additionally implemented a protected asset registry that prevents automated containment actions from affecting business-critical systems, and a human-in-the-loop requirement for all containment recommendations above a defined severity threshold, ensuring that AI augments human judgment rather than operating autonomously on the most consequential decisions.
Krushang Mandani is the CTO at KriraAI, driving innovation in AI-powered voice and automation solutions. He shares practical insights on conversational AI, business automation, and scalable tech strategies.